The auction house Bonhams in New York have just sold a handwritten scientific document written by Alan Turing, in which he worked on the foundations of mathematical notation and computer science, for $1,025,000. Before the auction Bonhams described the document as "Made up of 56 pages contained in a simple notebook bought from a stationers in Cambridge, UK, it is almost certainly the only extensive autograph manuscript by Turing in existence, and has never been seen in public. From internal evidence, it dates from 1942 when he was working at Bletchley Park to break the German Enigma Code, and provides remarkable insight into the thought process of a genius."
from The Universal Machine http://universal-machine.blogspot.com/
Voicecommand allows you to control your raspberry pi using only your voice. More information and videos on this can be found on my YouTube channel or the original blog posts.
Ive made a couple of key changes and their is a new option for people who want to help with the sox implementation to make the speech recognition more continuous rather than chunk-based.
The bug in the voicecommand -s hardware has been fixed.
Allows multilingual support with !lang and !language
Fixed casing bug when matching multiple variables
Install, Uninstall, and Update scripts are now seperated by project. So now if you want to only update youtube, just run UpdateAUISuite.sh youtube
tts and tts-nofill have been combined.
Moving away from yt.js to browse youtube in the browser. Now adding node.js youtube browsing API. See https://github.com/StevenHickson/RaspberryPiTV
Building https://github.com/StevenHickson/RaspberryPiTV to work with voicecommand and adding omxcontrols using https://github.com/StevenHickson/omxplayer_fifo
With the above, this allows a control panel that can control videos, play pandora, browse youtube, control music, and run voicecommand. Note that this is in beta and will require a lot of manual installation as their is no installation or readme yet (Hopefully soon to come).
Added youtube-dl cron update so that youtube-dl updates automatically every night. Often if someone says the youtube script doesnt work, it is because youtube-dl is out of date and YouTube has updated their security algorithms. Running sudo youtube-dl -U often fixes this problem.
Added an option in speech-recog.sh to use sox instead of arecord. Simply uncomment out the sox portion and comment the arecord portion in /usr/bin/speech-recog.sh as below:
Please let me know how this works for people so I can debug and get this working permanently. As always, you can find the install, update, and new YouTube videos at my YouTube channel here:
If you are wondering why Ive been so quiet, its because I moved, started grad school at Georgia Tech, and have been doing a technical review for a computer vision book.
Since Im a poor graduate student, please support my tinkering:
at Yescom USA. Valid until October 2013! Retractable Banner Stand at Yescom USA . Valid until October 2013!
The Guardian revealed last week that Apple is looking for a secure vehicle test track facility near SiliconValley. Therefore confirming the rumours that Apple is working on building a self-driving car. However, an article in The Verge warns Apple fans not to hold their breath. The development cycl e time from concept to production, for established car manufacturers, is in excess of 5 years. Apple has no experience in this market and consequently may be expected to take longer. Of course this may be like Apple Maps where Apple belatedly realised they strategically couldnt gift location support to Google and their established mapping product. Google, of course, has been developing driverless cars for ages. Apple has perhaps realised it cant leave this market segment to Google or risk just partnering with one car manufacturer.
from The Universal Machine http://universal-machine.blogspot.com/
To save the image, first click to enlarge the image, then right-click on it and click on Save Image As.. or simply right-click on the thumbnail and click on Save Link AS.. Note: all are high resolution images greater than 1024 x 728 px.
Posted by Adam Feldman, Product Manager and Pavel Simakov, Technical Lead, Course Builder Team
Over the past couple of years, Google’s Course Builder has been used to create and deliver hundreds of online courses on a variety of subjects (from sustainable energy to comic books), making learning more scalable and accessible through open source technology. With the help of Course Builder, over a million students of all ages have learned something new.
Today, we’re increasing our commitment to Course Builder by bringing rich, new functionality to the platform with a new release. Of course, we will also continue to work with edX and others to contribute to the entire ecosystem.
This new version enables instructors and students to understand prerequisites and skills explicitly, introduces several improvements to the instructor experience, and even allows you to export data to Google BigQuery for in depth analysis.
Drag and drop, simplified tabs, and student feedback
We’ve made major enhancements to the instructor interface, such as simplifying the tabs and clarifying which part of the page you’re editing, so you can spend more time teaching and less time configuring. You can also structure your course on the fly by dragging and dropping elements directly in the outline.
Additionally, we’ve added the option to include a feedback box at the bottom of each lesson, making it easy for your students to tell you their thoughts (though we cant promise youll always enjoy reading them).
Skill Mapping
You can now define prerequisites and skills learned for each lesson. For instance, in a course about arithmetic, addition might be a prerequisite for the lesson on multiplying numbers, while multiplication is a skill learned. Once an instructor has defined the skill relationships, they will have a consolidated view of all their skills and the lessons they appear in, such as this list for Power Searching with Google:
Instructors can then enable a skills widget that shows at the top of each lesson and which lets students see exactly what they should know before and after completing a lesson. Below are the prerequisites and goals for the Thinking More Deeply About Your Search lesson. A student can easily see what they should know beforehand and which lessons to explore next to learn more.
Skill maps help a student better understand which content is right for them. And, they lay the groundwork for our future forays into adaptive and personalized learning. Learn more about Course Builder skill maps in this video.
Analytics through BigQuery
One of the core tenets of Course Builder is that quality online learning requires a feedback loop between instructor and student, which is why we’ve always had a focus on providing rich analytical information about a course. But no matter how complete, sometimes the built-in reports just aren’t enough. So Course Builder now includes a pipeline to Google BigQuery, allowing course owners to issue super-fast queries in a SQL-like syntax using the processing power of Google’s infrastructure. This allows you to slice and dice the data in an infinite number of ways, giving you just the information you need to help your students and optimize your course. Watch these videos on configuring and sending data.
To get started with your own course, follow these simple instructions. Please let us know how you use these new features and what you’d like to see in Course Builder next. Need some inspiration? Check out our list of courses (and tell us when you launch yours).
This is the first entry of a series focused on Moore’s Law and its implications moving forward, edited from a White paper on Moore’s Law, written by Google University Relations Manager Michel Benard. This series quotes major sources about Moore’s Law and explores how they believe Moore’s Law will likely continue over the course of the next several years. We will also explore if there are fields other than digital electronics that either have an emerging Moores Law situation, or promises for such a Law that would drive their future performance.
---
Moores Law is the observation that over the history of computing hardware, the number of transistors on integrated circuits doubles approximately every two years. The period often quoted as "18 months" is due to Intel executive David House, who predicted that period for a doubling in chip performance (being a combination of the effect of more transistors and their being faster). -Wikipedia
Moore’s Law is named after Intel co-founder Gordon E. Moore, who described the trend in his 1965 paper. In it, Moore noted that the number of components in integrated circuits had doubled every year from the invention of the integrated circuit in 1958 until 1965 and predicted that the trend would continue "for at least ten years". Moore’s prediction has proven to be uncannily accurate, in part because the law is now used in the semiconductor industry to guide long-term planning and to set targets for research and development.
The capabilities of many digital electronic devices are strongly linked to Moores law: processing speed, memory capacity, sensors and even the number and size of pixels in digital cameras. All of these are improving at (roughly) exponential rates as well (see Other formulations and similar laws). This exponential improvement has dramatically enhanced the impact of digital electronics in nearly every segment of the world economy, and is a driving force of technological and social change in the late 20th and early 21st centuries.
Most improvement trends have resulted principally from the industry’s ability to exponentially decrease the minimum feature sizes used to fabricate integrated circuits. Of course, the most frequently cited trend is in integration level, which is usually expressed as Moore’s Law (that is, the number of components per chip doubles roughly every 24 months). The most significant trend is the decreasing cost-per-function, which has led to significant improvements in economic productivity and overall quality of life through proliferation of computers, communication, and other industrial and consumer electronics.
Transistor counts for integrated circuits plotted against their dates of introduction. The curve shows Moores law - the doubling of transistor counts every two years. The y-axis is logarithmic, so the line corresponds to exponential growth
All of these improvement trends, sometimes called “scaling” trends, have been enabled by large R&D investments. In the last three decades, the growing size of the required investments has motivated industry collaboration and spawned many R&D partnerships, consortia, and other cooperative ventures. To help guide these R&D programs, the Semiconductor Industry Association (SIA) initiated the National Technology Roadmap for Semiconductors (NTRS) in 1992. Since its inception, a basic premise of the NTRS has been that continued scaling of electronics would further reduce the cost per function and promote market growth for integrated circuits. Thus, the Roadmap has been put together in the spirit of a challenge—essentially, “What technical capabilities need to be developed for the industry to stay on Moore’s Law and the other trends?”
In 1998, the SIA was joined by corresponding industry associations in Europe, Japan, Korea, and Taiwan to participate in a 1998 update of the Roadmap and to begin work toward the first International Technology Roadmap for Semiconductors (ITRS), published in 1999. The overall objective of the ITRS is to present industry-wide consensus on the “best current estimate” of the industry’s research and development needs out to a 15-year horizon. As such, it provides a guide to the efforts of companies, universities, governments, and other research providers or funders. The ITRS has improved the quality of R&D investment decisions made at all levels and has helped channel research efforts to areas that most need research breakthroughs.
For more than half a century these scaling trends continued, and sources in 2005 expected it to continue until at least 2015 or 2020. However, the 2010 update to the ITRS has growth slowing at the end of 2013, after which time transistor counts and densities are to double only every three years. Accordingly, since 2007 the ITRS has addressed the concept of functional diversification under the title “More than Moore” (MtM). This concept addresses an emerging category of devices that incorporate functionalities that do not necessarily scale according to “Moores Law,” but provide additional value to the end customer in different ways.
The MtM approach typically allows for the non-digital functionalities (e.g., RF communication, power control, passive components, sensors, actuators) to migrate from the system board-level into a particular package-level (SiP) or chip-level (SoC) system solution. It is also hoped that by the end of this decade, it will be possible to augment the technology of constructing integrated circuits (CMOS) by introducing new devices that will realize some “beyond CMOS” capabilities. However, since these new devices may not totally replace CMOS functionality, it is anticipated that either chip-level or package level integration with CMOS may be implemented.
The ITRS provides a very comprehensive analysis of the perspective for Moore’s Law when looking towards 2020 and beyond. The analysis can be roughly segmented into two trends: More Moore (MM) and More than Moore (MtM). In the next blog in this series, we will look in the the recent conclusions mentioned in the ITRS 2012 report on both trends.
The opportunities for more discourse on the impact and future of Moore’s Law on CS and other disciplines are abundant, and can be continued with your comments on the Research at Google Google+ page. Please join, and share your thoughts.
Posted by Luc Vincent, Engineering Director, Geo Imagery
This year the Google Earth Engine team attended the European Geosciences Union General Assembly meeting in Vienna, Austria to engage with a number of European geoscientific partners. This was just the first of a series of European summits the team has attended over the past few months, including, most recently, the IEEE Geoscience and Remote Sensing Society meeting held last week in Milan, Italy.
Noel Gorelick presenting Google Earth Engine at EGU 2015.
We are very excited to be collaborating with many European scientists from esteemed institutions such as the European Commission Joint Research Centre, Wageningen University, and University of Pavia. These researchers are utilizing the Earth Engine geospatial analysis platform to address issues of global importance in areas such as food security, deforestation detection, urban settlement detection, and freshwater availability.
Thanks to the enlightened free and open data policy of the European Commission and European Space Agency, we are pleased to announce the availability of Copernicus Sentinel-1 data through Earth Engine for visualization and analysis. Sentinel-1, a radar imaging satellite with the ability to see through clouds, is the first of at least 6 Copernicus satellites going up in the next 6 years.
Sentinel-1 data visualized using Earth Engine, showing Vienna (left) and Milan (right).
Wind farms seen off the Eastern coast of England.
This radar data offers a powerful complement to other optical and thermal data from satellites like Landsat, that are already available in the Earth Engine public data catalog. If you are a geoscientist interested in accessing and analyzing the newly available EC/ESA Sentinel-1 data, or anything else in our multi-petabyte data catalog, please sign up for Google Earth Engine.
We look forward to further engagements with the European research community and are excited to see what the world will do with the data from the European Unions Copernicus program satellites.
This site serves as our jumping off point for all of our lessons and projects. Instead of a text book we have web pages with instructions, examples, links and videos. If you are ever unsure of what you need to do, check this site first.
Should there ever be a substitute on a computer day, all your instructions for the day will be on this home page. We are beginning our computer class this year with typing practice. Learning to type fast is so important for todays world and the future. It takes practice to get faster. No matter how fast you type now, your goal for this unit is to improve your personal speed.
Click on your grade level above and then click on Unit 1.
Posted by Maggie Johnson, Director of Education and University Relations, Google
(Cross-posted on the Google for Education Blog)
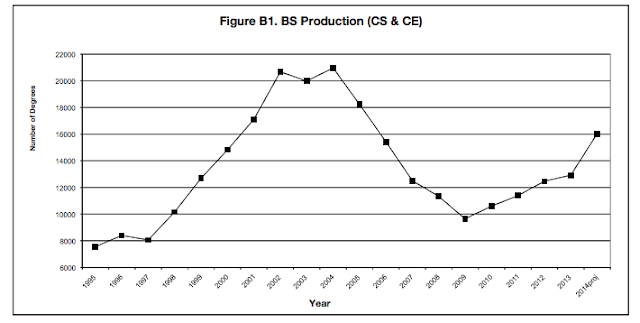
For many years, the Computer Science industry has struggled with a pipeline problem. Since 2009, when the number of undergraduate computer science (CS) graduates hit a low mark, there have been many efforts to increase the supply to meet an ever-increasing demand. Despite these efforts, the projected demand over the next seven years is significant.
Source: 2013 Taulbee Survey, Computing Research Association
Even if we are able to sustain a positive growth in graduation rates over the next 7 years, we will only fill 30-40% of the available jobs.
“By 2022, the computer and mathematical occupations group is expected to yield more than 1.3 million job openings. However, unlike in most occupational groups, more job openings will stem from growth than from the need to replace workers who change occupations or leave the labor force.” -Bureau of Labor Statistics Occupational Projection Report, 2012.
More than 3 in 4 of these 1.3M jobs will require at least a Bachelor’s degree in CS or an Information Technology (IT) area. With our current production of only 16,000 CS undergraduates per year, we are way off the mark. Furthermore, within this too-small pipeline of CS graduates, is an even smaller supply of diverse - women and underrepresented minority (URM) - students. In 2013, only 14% of graduates were women and 20% URM. Why is this lack of representation important?
The workforce that creates technology should be representative of the people who use it, or there will be an inherent bias in design and interfaces.
If we get women and URMs involved, we will fill more than 30-40% of the projected jobs over the next 7 years.
Getting more women and URMs to choose computing occupations will reduce social inequity, since computing occupations are among the fastest-growing and pay the most.
Why are so few students interested in pursuing computing as a career, particularly women and URMs? How did we get here?
One fundamental reason is the lack of STEM (Science, Technology, Engineering and Mathematics) capabilities in our younger students. Over the last several years, international comparisons of K12 students’ performance in science and mathematics place the U.S. in the middle of the ranking or lower. On the National Assessment of Educational Progress, less than one-third of U.S. eighth graders show proficiency in science and mathematics. Lack of proficiency has led to lack of engagement in technical degree programs, which include CS and IT.
“In the United States, about 4% of all bachelor’s degrees awarded in 2008 were in engineering. This compares with about 19% throughout Asia and 31% in China specifically. In computer sciences, the number of bachelor’s and master’s degrees awarded decreased sharply from 2004 to 2007.” -NSF: Higher Education in Science and Engineering.
The lack of proficiency has had a substantial impact on the overall number of students pursuing technical careers, but there have also been shifts resulting from trends and events in the technology sector that compound the issue. For example, we saw an increase in CS graduates from 1997 to the early 2000’s which reflected the growth of the dot-com bubble. Students, seeing the financial opportunities, moved increasingly toward technical degree programs. This continued until the collapse, after which a steady decrease occurred, perhaps as a result of disillusionment or caution.
Importantly, there are additional factors that are minimizing the diversity of individuals, particularly women, pursuing these fields. It’s important to note that there are no biological or cognitive reasons that justify a gender disparity in individuals participating in computing (Hyde 2006). With similar training and experience, women perform just as well as men in computer-related activities (Margolis 2003). But there can be important differences in reinforced predilections and interests during childhood that affect the diversity of those choosing to pursue computer science .
In general, most young boys build and explore; play with blocks, trains, etc.; and engage in activity and movement. For a typical boy, a computer can be the ultimate toy that allows him to pursue his interests, and this can develop into an intense passion early on. Many girls like to build, play with blocks, etc. too. For the most part, however, girls tend to prefer social interaction. Most girls develop an interest in computing later through social media and YouTubers, girl-focused games, or through math, science and computing courses. They typically do not develop the intense interest in computing at an early age like some boys do – they may never experience that level of interest (Margolis 2003).
Thus, some boys come into computing knowing more than girls because they have been doing it longer. This can cause many girls to lose confidence and drive during adolescence with the perception that technology is a man’s world - Both girls and boys perceive computing to be a largely masculine field (Mercier 2006). Furthermore, there are few role models at home, school or in the media changing the perception that computing is just not for girls. This overall lack of support and encouragement keeps many girls from considering computing as a career. (Google white paper 2014)
In addition, many teachers are oblivious to or support the gender stereotypes by assigning problems and projects that are oriented more toward boys, or are not of interest to girls. This lack of relevant curriculum is important. Many women who have pursued technology as a career cite relevant courses as critical to their decision (Liston 2008).
While gender differences exist with URM groups as well, there are compelling additional factors that affect them. Jane Margolis, a senior researcher at UCLA, did a study in 2000 resulting in the book Stuck in the Shallow End. She and her research group studied three very different high schools in Los Angeles, with different student demographics. The results of the study show that across all three schools, minority students do not get the same opportunities. While all of the students have access to basic technology courses (word processor, spreadsheet skills, etc.), advanced CS courses are typically only made available to students who, because of opportunities they already have outside school, need it less. Additionally, the best and most enthusiastic minority students can be effectively discouraged because of systemic and structural issues, and belief systems of teachers and administrators. The result is a small, mostly homogeneous group of students have all the opportunities and are introduced to CS, while the rest are relegated to the “shallow end of computing skills”, which perpetuates inequities and keeps minority students from pursuing computing careers.
These are some of the reasons why the pipeline for technical talent is so small and why the diversity pipeline is even smaller. Over the last two years, however, we are starting to see some positive signs.
Many students are becoming more aware of the relevance and accessibility of coding through campaigns such as Hour of Code and Made with Code.
This increase in awareness has helped to produce a steady increase in CS and IT graduates, and there’s every indication this growth will continue.
More opportunities to participate in CS-related activities are becoming available for girls and URMs, such as CS First, Technovation, Girls who Code, Black Girls Code, #YesWeCode, etc.
There’s much more that can be done to reinforce these positive trends, and to get more students of all types to pursue computing as a career. This is important not only to high tech, but is critical for our nation to compete globally. In the next post of this series, we will explore some of the positive steps that have been taken in increasing the diversity of graduates in Computer Science (CS) and Information Technology (IT) fields.
Posted by Adam Feldman, Product Manager and Pavel Simakov, Technical Lead, Course Builder Team
(Cross-posted on the Google for Education Blog)
When we last updated Course Builder in April, we said that its skill mapping capabilities were just the beginning. Today’s 1.9 release greatly expands the applicability of these skill maps for you and your students. We’ve also significantly revamped the instructor’s user interface, making it easier for you to get the job done while staying out of your way while you create your online courses.
First, a quick update on project hosting. Course Builder has joined many other Google open source projects on GitHub (download it here). Later this year, we’ll consolidate all of the Course Builder documentation, but for now, get started at Google Open Online Education.
Now, about those features:
Measuring competence with skill maps In addition to defining skills and prerequisites for each lesson, you can now apply skills to each question in your courses’ assessments. By completing the assessments and activities, learners will be able to measure their level of competence for each skill. For instance, here’s what a student taking Power Searching with Google might see:
This information can help guide them on which sections of the course to revisit. Or, if a pre-test is given, students can focus on the lessons addressing their skill gaps.
To determine how successful the content is at teaching the desired skills across all students, an instructor can review students’ competencies on a new page in the analytics section of the dashboard.
Improving usability when creating a course Course Builder has a rich set of capabilities, giving you control over every aspect of your course -- but that doesn’t mean it has to be hard to use. Our goal is to help you spend less time setting up your course and more time educating your students. We’ve completely reorganized the dashboard, reducing the number of tabs and making the settings you need clearer and easier to find.
We also added in-place previewing, so you can quickly edit your content and immediately see how it will look without needing to reload any pages.
For a full list of the other features added in this release (including the ability for students to delete their data upon unenrollment and removal of the old Files API), see the release notes. As always, please let us know how you use these new features and what you’d like to see in Course Builder next to help make your online course even better.
In the meantime, take a look at a couple recent online courses that we’re pretty excited about: Sesame Street’s Make Believe with Math and our very own Computational Thinking for Educators.
Posted by Linne Ha, Senior Program Manager, Google Research for Low Resource Languages
Building a decent text-to-speech (TTS) voice for any language can be challenging, but creating one – a good, intelligible one – for a low resource language can be downright impossible. By definition, working with low resource languages can feel like a losing proposition – from the get go, there is not enough audio data, and the data that exists may be questionable in quality. High quality audio data, and lots of it, is key to developing a high quality machine learning model. To make matters worse, most of the world’s oldest, richest spoken languages fall into this category. There are currently over 300 languages, each spoken by at least one million people, and most will be overlooked by technologists for various reasons. One important reason is that there is not enough data to conduct meaningful research and development.
Project Unison is an on-going Google research effort, in collaboration with the Speech team, to explore innovative approaches to building a TTS voice for low resource languages – quickly, inexpensively and efficiently. This blog post will be one of several to track progress of this experiment and to share our experience with the research community at large – our successes and failures in a trial and error, iterative approach – as our adventure plays out.
One of the most critical aspects of building a TTS system is acquiring audio data. The traditional way to do this is in a professional recording studio with a voice talent, sound engineer and a voice director. The process can take considerable time and can be quite expensive. People often mistake voice talent work to be similar to a news reader, but it is highly specialized and the work can be very difficult.
Such investments in time and money may yield great audio, but the catch is that even if you’ve created the best TTS voice from these recordings, at best it will still sound exactly like the voice talent - the person who provided the raw audio data. (We’ve read the articles about people who have fallen for their GPS voice to find that they are real people with real names.) So the interesting problem here from a research perspective is how to create a voice that sounds human but is not identifiable as a singular person.
Crowd-sourcing projects for automatic speech recognition (ASR) for Google Voice Search had been successful in the past, with public volunteers eager to participate by providing voice samples. For ASR, the objective is to collect from a diversity of speakers and environments, capturing varying regional accents. The polar opposite is true of TTS, where one unique speaker, with the standard accent and in a soundproof studio is the basic criteria.
Many years ago, Yannis Agiomyrgiannakis, Digital Signal Processing researcher on the TTS team in Google London, wrote a “manifesto” for acoustic data collection for 2000 languages. In his document, he gave technical specifications on how to convert an average room into a recording studio. Knot Pipatsrisawat, software engineer in Google Research for Low Resource Languages, built a tool that we call “ChitChat”, a portable recording studio, using Yannis’ specifications. This web app allows users to read the prompt, playback the recording and even assess the noise level of the room.
From other past research in ASR, we knew that the right tool could solve the crowd sourcing problem. ChitChat allowed us to experiment in different environments to get an idea of what kind of office space would work and what kind of problems we might encounter. After experimenting with several different laptops and tablets, we were able to find a computer that recognized the necessary peripherals (the microphone, USB converter, and preamp) for under $2,000 – much cheaper than a recording studio!
Now we needed multiple speakers of a single language. For us, it was a no-brainer to pilot Project Unison with Bangladeshi Googlers, all of whom are passionate about getting Google products to their home country (the success of Android products in Bangladesh is an example of this). Googlers by and large are passionate about their work and many offer their 20% time as a way to help, to improve or to experiment on something that may or may not work because they care. The Bangladeshi Googlers are no exception. They embodied our objectives for a crowdsourcing innovation: out of many, we could achieve (literally) one voice.
With multiple speakers, we would target speakers of similar vocal profiles and adapt them to create a blended voice. Statistical parametric synthesis is not new, but the advances in recent technology have improved quality and proved to be a lightweight solution for a project like ours.
In May of this year, we auditioned 15 Bangaldeshi Googlers in Mountain View. From these recordings, the broader Bangladeshi Google community voted blindly for their preferred voice. Zakaria Haque, software engineer in Machine Intelligence, was chosen as our reference for the Bangla voice. We then narrowed down the group to five speakers based on these criteria: Dhaka accent, male (to match Zakaria’s), similarity in pitch and tone, and availability for recordings. The original plan of a spectral analysis using PRAAT proved to be unnecessary with our limited pool of candidates.
All 5 software engineers – Ahmed Chowdury, Mohammad Hossain, Syeed Faiz, Md. Arifuzzaman Arif, Sabbir Yousuf Sanny – plus Zakaria Haque recorded over 3 days in the anechoic chamber, a makeshift sound-proofed room at the Mountain View campus just before Ramadan. HyunJeong Choe, who had helped with the Korean TTS recordings, directed our volunteers.
Left: TPM Mohammad Khan measures the distance from the speaker to the mic to keep the sound quality consistent across all speakers. Right: Analytical Linguist HyunJeong Choe coaches SWE Ahmed Chowdury on how to speak in a friendly, knowledgeable, "Googly" voice
ChitChat allowed us to troubleshoot on the fly as recordings could be monitored from another room using the admin panel. In total, we recorded 2000 Bangla and English phrases mined from Wikipedia. In 30-60 minute intervals, the participants recorded over 250 sentences each.
In this session, we discovered an issue: a sudden drop in amplitude at high frequencies in a few recordings. We were worried that all the recordings might have to be scrapped.
As illustrated in the third image, speaker3 has a drop in energy above 13kHz which is visible in the graph and may be present at speech, distorting the speaker’s voice to sound as if he were speaking through a tube.
Another challenge was that we didn’t have a pronunciation lexicon for Bangla as spoken in Bangladesh. We worked initially with the publicly available TTS data from the Indian Institute of Information Technology, but this represented the variant of Bangla spoken in West Bengal (India), which differs from the speech we recorded. Our internally designed pronunciation rules for Bengali were also aimed at West Bengal and would need to be revised later.
Deciding to proceed anyway, Alexander Gutkin, Speech software engineer and lead for TTS for Low Resource Languages in Google London, built an initial prototype voice. Using the preliminary text normalization rules created by Richard Sproat, Speech and Language Processing researcher, the first voice we attempted proved to be surprisingly good. The problem in the high frequencies we had seen in the recordings is undetectable in the parametric voice. When we return to the sound studio to record an additional 200 longer sentences, we plan to try an upgrade of the USB converter. Meanwhile, Martin Jansche, Natural Language Understanding software engineer, has worked with a team of native speakers on a pronunciation and lexicon and model that better matches the phonology of colloquial Bangladeshi Bangla. Alexander will use the additional recordings and the new pronunciation dictionary to build the second version.
NEXT UP: Building a parametric voice with multiple speaker data (Ep.2)
Package include bag, battery and charger. OS Windows Vista Ultimate. Outlook: not very bad Battery: long 1 hour system and hardware: still in good condition (never broken) Warranty: 1 Month
contact: Mr Zul 0127319949 COD Area: Segamat or Tmn Universiti, Skudai or Bandar Mas, Kota Tinggi Johor Payment: Bank transfer or cash
King of Fighters Wing 1.8 is the 1.8 version of King of Fighters Wing game with new character Haohmaru from classic arcade fighting game Samurai Shodown added to the gameplay. Haohmaru is a star character of Samurai Shodown series and is one of the most known characters in this series. In this version of KOF Wing game, new skills are also added to some characters. King of Fighters Wing is a very nice flash remake of the classic arcade fighting game King of Fighters or KOF. KOF Wing 1.8 is in Chinese, so if you do not know Chinese and you are not an experienced player of King of Fighters Wing game, it is recommended that you play the King of Fighters Wing 1.0 Demo, which has English option, first to get familiar with the game controls.
The special move key combinations for character Haohmaru are shown in the following chat. In this chart, K means strong kick, K_l means light kick, P means strong punch, P_l means light punch. H key means hack, and S1 means power burst. If you choose normal key mode in the game menu, you need to use the normal key mode combinations. If you choose simple key mode in the game menu, you need to use the simple key mode combinations.


























 Price : RM 750
Price : RM 750 













